
Blog: On the drawbacks of FedAvg and the benefits of Posterior Averaging
A visual study of FedAvg and the Posterior in Federated Learning
| Author | Date | Vacancy | Reading time |
|---|---|---|---|
| Michael Feil | July 14th 2021 | Federated Learning in Healthcare, TU Munich | 20min |
Table of Contents:
- Part 0: Introduction
- Part 1: Create non-iid client distributions
- Part 2. Apply gradient descent for one client
- 2.1: Right on track: gradient descent ftw!
- 2.2: Taking the detour: an intro to gradient descent in python
- 2.3: Gradient descent for both clients and the global distribution
- Part 3: FedAvg with non-iid client data
- 3.1: Taking the detour: An programming intro to FedAvg
- 3.2: Back on track: Federated Averaging
- 3.3: How to mess with Federated Averaging
- Part 4: Our salvation: Posterior Averaging?
- 4.1: FedPA: Beyond the simplified implementation
- Part 5: Summary
- Part 6: References
Hint: For interactivity, better open this blog post on Binder.org. Simply press on this logo: ![]()
Part 0: Introduction
Think about the following scenario:
You have personal images on your smartphone. So do your friends. (of course they do, we live in 2021!) As a Machine Learning engineer your goal is to create a machine learning model, which does a good job at the classification of your images from your phone and automatically clusters them in various folders, e.g. “cats” and “beergarden munich”. You also plan to help some of your friends sorting their images.
In the past (or better say before 2017), your proposal would have been, that everyone of your friends would have uploaded their images to your cloud-based server. Then all of images would get aggregated, and you would train and test a ML model. There was just one drawback: None of our friends wanted to share their sensitive image data! - But now you have the answer: Federated Learning (FL)!
The introduction of Federated Averaging (FedAvg) by McMahan et al.[2] in 2017 enables us now, to train a model without uploading any images to any kind of central server. Isn’t that great!?! Let’s look at the images below.
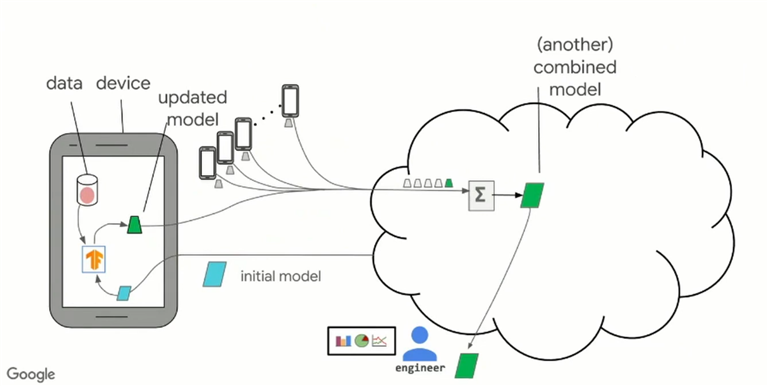
As in the Figure1 above, in the case of cross-device FL with FedAvg, our cloud-based central server will send an initial state of the model parameters to thousands of mobile devices at once. The clients then update their version of the model parameters using stochastic gradient descent (SGD). By doing more SGD steps, we train more each communication round, and therefore improve the communication efficiency. The updated model parameters get communicated back to the central server, where the client parameters get aggregated using weighted averaging. The process then starts again into the next communication round with the slightly improved parameters of our model.
Executive Summary
In the following sections, we will discuss a suitable heterogenous data distribution for the clients Part 1, code and visualize gradient descent and derive the global posterior in Part 2. In Part 3, we will find some unexpected hiccups using FedAvg[2] and solve them by introducing a FedPA[1] in Part 4.
# import some utilities
from computation_fedavg_gd import grad_descent, partial_derivative
from computation_fedavg_gd import MultivariateGaussian
from computation_fedavg_gd import PDFsManipulate
# import the usual suspects (excluding pandas as pd)
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
Part 1: Create non-iid client distributions
First step: For our scenario from the introduction, we model two phones (clients) by selecting two suitable client distributions. The distributions symbolize our target function on each client, which we try to optimize. For this notebook, we plot with the following assumptions:
- the model has just 2 tunable weights $\theta$
- there are 2 clients.
- The $\theta$ over each target function $J$ has a (Multivariate) Gaussian distribution ($\mu$,$\Sigma$).
- since the data distribution of our clients differs, we assume a non independent and identically distributed $\theta$ (non-iid) (i.e. we pick different parameters $\mu$, $\Sigma$ for each client).
Further reading: The Multivariate Gaussian is defined in computation_fedavg_gd.py according to this formula:
# If you are running this notebook blog interactivly on binder.org
# after reading through everything, you can change the parameters here.
mu1, sigma1 = np.array([0, 1]), np.array([[1.0, -0.9], [-0.5, 1.5]])
mu2, sigma2 = np.array([0, -1.2]), np.array([[1.5, 0.6], [0.9, 1.0]])
multivariate1 = MultivariateGaussian(
mu=mu1, sigma=sigma1
)
multivariate2 = MultivariateGaussian(
mu=mu2, sigma=sigma2
)
# calculate at our target function over a sampling grid
from plot_fedavg_gd import SAMPLE_GRID_VECTOR
# sample over a grid from -3,5 to 3,5 in 2D
J1 = multivariate1.evaluate(theta_vec=SAMPLE_GRID_VECTOR)
J2 = multivariate2.evaluate(theta_vec=SAMPLE_GRID_VECTOR)
print(f"evaluated gaussian over a 2D sampling grid {SAMPLE_GRID_VECTOR.shape} for a third target vector {J1.shape}")
evaluated gaussian over a 2D sampling grid (71, 71, 2) for a third target vector (71, 71)
Lets create some fancy 3D-plots for our two client distributions. Note how the two distributions have different optima in our non-iid setting.
%matplotlib notebook
# lets visualize our distributions
def client_function_draw(eval_sample, cmap = matplotlib.cm.Greens):
# adjust some 3D settings
fig = plt.figure()
ax = fig.gca(projection="3d")
ax.view_init(elev=20.0, azim=-125)
ax.dist = 7.5
ax.set_zticks(np.linspace(0, 0.3, 7))
# labels
ax.set_xlabel(r"${\theta}_0$")
ax.set_ylabel(r"${\theta}_1$")
ax.set_zlabel(r"J(${\theta}_0$, ${\theta}_1$)")
# plot a 3D curve
ax.plot_wireframe(
SAMPLE_GRID_VECTOR[:,:,0],
SAMPLE_GRID_VECTOR[:,:,1],
eval_sample,
rstride=3,
cstride=3,
linewidth=0.5,
antialiased=True,
cmap=matplotlib.cm.Greens,
zorder=1,
)
# make a 2D contour plot in cmap color on the bottom
ax.contourf(
SAMPLE_GRID_VECTOR[:,:,0],
SAMPLE_GRID_VECTOR[:,:,1],
eval_sample,
zdir="z",
offset=-np.max(eval_sample)/20,
cmap=cmap,
zorder=0,
)
return ax
print("**client 1: **")
fig = client_function_draw(J1)
print("**client 2: **")
fig = client_function_draw(J2, cmap="Oranges")
**client 1: **

**client 2: **

Part 2. Apply gradient descent for one client
Second step: Awesome, we have the parameter spaces for our two image recognition models. Let’s do some training, every client simply by himself, with its own local data. If you don’t know how gradient descent is implemented here, a quick detour to 2.2. might help! :)
2.1 Right on track: gradient descent ftw!
Let’s see how this would look like, with Gradient Descent applied.
# lets start with some random values for theta. come back later, and tune them, if you like.
THETA = np.array([-2.0, 0.1])
%matplotlib notebook
# apply gradient descent
history_client1 = grad_descent(
function_descent=multivariate1.evaluate,
theta=THETA,
eps=1e-07, # stop condition
nb_max_iter=1000, # max iterations,
verbose=1,
)
ax = client_function_draw(J1)
# plot the gradient descent
ax.scatter(
history_client1[:, 0][::10],
history_client1[:, 1][::10],
history_client1[:, 2][::10],
label="GD descent",
c="red",
lw=5,
zorder=100,
)
fig = ax.legend()
iter: 0, theta: [-1.9, gradient: 3.313123563351253e-05
iter: 50, theta: [-1.6, gradient: 0.00018967341849882979
iter: 100, theta: [-0.9, gradient: 0.0025225717318137636
iter: 150, theta: [-0.2, gradient: 0.00034660933191360543
iter: 200, theta: [-0.0, gradient: 1.3755523300240657e-05
iter: 250, theta: [-0.0, gradient: 3.125739587883647e-06
iter: 300, theta: [-0.0, gradient: 8.610496716188187e-07
iter: 350, theta: [-0.0, gradient: 2.3839203919240326e-07
stop condition reached after 384 iterations

Awesome. In the next field, we also visualize the second client, together with our first. This gives us an overview about the shifted distributions and our non-iid setting.
from plot_fedavg_gd import mpl_multivariate_3d_gd
print("**client 1**")
# settings of plotting client 1
fig = mpl_multivariate_3d_gd(
name_labels=["GD client 1"],
colors=["green"],
functions=[multivariate1.evaluate],
target_function=[J1],
cmap_target=[ "Greens"],
label_target=[ "client 1 target"],
theta=THETA,
)
print("**client 2**")
fig = mpl_multivariate_3d_gd(
name_labels=["GD client 2", ],
colors=["orange", ],
functions=[multivariate2.evaluate],
target_function=[J2],
cmap_target=["Oranges"],
label_target=["client 2 target"],
theta=THETA,
)
**client 1**
create 3D plot using SGD on [('GD client 1', 'green')] over distribution [('client 1 target', 'Greens')]

**client 2**
create 3D plot using SGD on [('GD client 2', 'orange')] over distribution [('client 2 target', 'Oranges')]

As you can see, each client problem by itself is solved. In our case, the challenge however is, to find the global optimum of a global model. By searching for one single and global model, we have more data availabe to fit our model to. We therefore ‘hope’ to generalize better to new clients in the future, or get a better overall performance on our exisiting clients.
2.2 Taking the detour: an intro to gradient descent in Python
If you are not in a hurry, you can see in this chapter how gradient descent has been implemented.
We optimize one parameter at a time. (line-search)
- for all $\theta_i$ in vector $\theta$ do: \(\theta_{i, new} \leftarrow \theta_{i}- \alpha_{lr} \nabla \theta_{i}\)
GD: linea-search for n iterations over one function
# Usage of line-search: optimize one parameter at a time
partial_derivative??
# Evaluating gradient descent for one function:
grad_descent??
2.3: Deriving the global posterior distribution
Lets add two target functions client1 + client2 together! We do as if we could aggregate our clients images, and could train a central model without Federated Learning.
We assume to have a uniform prior for the weight distributions of our clients. That way, our global posterior distribution does not depend on any client priors and exactly decomposes into a product of local posteriors. [1] \(\mathbb{P}_{global}(\boldsymbol{\theta} \mid D) \propto \prod_{i=1}^{N} \mathbb{P}\left(\boldsymbol{\theta} \mid D_{i}\right)\)
We further assumed to have two Gaussian distrbutions on our clients. Luckily, we can look up in the Matrix Cookbook [5] (Section 8.1.8), how to calculate the global posterior from a product of gaussians:
Posterior: A Product of gaussian densities
Let $\mathcal{N}_{\mathbf{x}}(\mathbf{\mu}, \mathbf{\Sigma})$ denote a density of $\mathbf{x}$, then \(\begin{aligned} c_{c} \mathcal{N}_{\mathbf{x, global}}\left(\mathbf{\mu}_{c}, \mathbf{\Sigma}_{c}\right) = \mathcal{N}_{\mathbf{x, client1}}\left(\mathbf{\mu}_{1}, \mathbf{\Sigma}_{1}\right) \cdot \mathcal{N}_{\mathbf{x, client2}}\left(\mathbf{\mu}_{2}, \mathbf{\Sigma}_{2}\right) \\ \end{aligned}\)
Awesome, the product is again a Gaussian. All we need to do is to compute the normalization constant $c_{c}$ , plus our $ \mathbf{\mu}{c}$ and $ \mathbf{\Sigma}{c} $ of the new distribution:
\[\begin{aligned} \mathbf{\mu}_{c}=&\left(\boldsymbol{\Sigma}_{1}^{-1}+\boldsymbol{\Sigma}_{2}^{-1}\right)^{-1}\left(\boldsymbol{\Sigma}_{1}^{-1} \mathbf{\mu}_{1}+\boldsymbol{\Sigma}_{2}^{-1} \mathbf{\mu}_{2}\right) \\ \boldsymbol{\Sigma}_{c}=&\left({\boldsymbol{\Sigma}}_{1}^{-1}+{\boldsymbol{\Sigma}}_{2}^{-1}\right)^{-1} \end{aligned}\]The normalization constant is optionally calculated using the following equation:
\[\begin{aligned} c_{c}=\mathcal{N}_{x = \mathbf{\mu}_{1}}\left(\mathbf{\mu}_{2},\left(\boldsymbol{\Sigma}_{1}+\boldsymbol{\Sigma}_{2}\right)\right) = \frac{1}{\sqrt{\operatorname{det}\left(2 \pi\left(\boldsymbol{\Sigma}_{1}+\mathbf{\Sigma}_{2}\right)\right)}} \exp \left[-\frac{1}{2}\left(\mathbf{\mu}_{1}-\mathbf{\mu}_{2}\right)^{T}\left(\boldsymbol{\Sigma}_{1}+\boldsymbol{\Sigma}_{2}\right)^{-1}\left(\mathbf{\mu}_{1}-\mathbf{\mu}_{2}\right)\right] \\ \end{aligned}\]Posterior: Numeric calculation by multiplication
But we could also do it numerically, by just calculating: \(\mathbb{P}_{global} = \frac{(multivariate1.evaluate * multivariate2.evaluate)} {c_{normalize}}\)
# Numeric calculation of our Posterior
# basically does (multivariate1 + multivariate2) / norm
f_posterior_num = PDFsManipulate(functions=[multivariate1.evaluate, multivariate2.evaluate], method = np.multiply)
# evaluate on SAMPLE_GRID
J = f_posterior_num.evaluate(theta_vec = SAMPLE_GRID_VECTOR)
# Exact calculation of our Posterior, using the equations above.
inv_sigma1 = np.linalg.inv(sigma1)
inv_sigma2 = np.linalg.inv(sigma2)
sum_inv = np.linalg.inv(inv_sigma1 + inv_sigma2)
sigma_global_posterior = sum_inv
mu_global_posterior = sum_inv @ (inv_sigma1 @ mu1 + inv_sigma2 @ mu2)
# using the math above
f_posterior_exact = MultivariateGaussian(
mu=mu_global_posterior,
sigma=sigma_global_posterior
)
# evaluate on SAMPLE_GRID
J_exact = f_posterior_exact.evaluate(theta_vec = SAMPLE_GRID_VECTOR)
print("argmax J_exact", np.where(J_exact==J_exact.max()),J_exact.max())
print("argmax J_num", np.where(J==J.max()),J.max())
ax = client_function_draw(J_exact, cmap="Purples")
# ax = client_function_draw(J, cmap="Purples")
argmax J_exact (array([33], dtype=int64), array([42], dtype=int64)) 0.39885406077586116
argmax J_num (array([32], dtype=int64), array([41], dtype=int64)) 0.3949362773624632

By having the $\Sigma_{global}$ and $\mu_{global}$, we can reconstruct the global posterior, finding the same argmax as with the numerical calculations.
Once we have the posterior, we can run even GD on it, or directly go to the argmax at $\mu$ of the f_posterior_exact:
#lets do, as if we could aggregate our global function
fig = mpl_multivariate_3d_gd(
name_labels=["GD on global posterior", "GD client 2", "GD client 1"],
colors=["purple", "orange", "green"],
functions=[f_posterior_exact.evaluate, multivariate1.evaluate, multivariate2.evaluate],
target_function=[ J1, J2, J_exact],
cmap_target=[ "Greens", "Oranges", "Purples"],
label_target=[ "client 1 target", "client 2 target", "global posterior"],
theta=THETA,
)
create 3D plot using SGD on [('GD on global posterior', 'purple'), ('GD client 2', 'orange'), ('GD client 1', 'green')] over distribution [('client 1 target', 'Greens'), ('client 2 target', 'Oranges'), ('global posterior', 'Purples')]

Part 3: FedAvg with non-iid client data
Below, there is a short intro on how FedAvg is implemented. Feel free to skip to 3.2. if you have seen it before.
3.1 Taking the detour: A programming intro to FedAvg
FedAvg basically works like this algorithm below. We initialize some theta on the server, and send it to our two clients. Each client does then a short time of training by using gradient decent. Then we send back our theta from each of the clients and average the results on the server. Voila! We improved our theta model weights a bit. If we do it repeatedly, we hopefully get to a good model in the end.
theta = [theta0, theta1]
nb_rounds = 10
gd_steps_local = 20
def client_update(theta):
"""on the clients"""
client_data = client.get_distribution() # get the client data
# update the parameters
for i in range(gd_steps_local):
theta = grad_descent(client_data, theta, nb_steps=1)
# send back the most recent model
return theta
def fedavg_server_update(theta_0):
"""on the server"""
theta_server = theta_0
for i in range(nb_rounds):
# in parallel
theta_client1 = client1.client_update(theta_server)
theta_client2 = client2.client_update(theta_server)
# receive on server
theta_server = average(theta_client1, theta_client2)
# output best model at the end of training
return theta_server
# optional, get the source code
from computation_fedavg_gd import fedavg
fedavg??
3.2 Back on track: Federated Averaging
Remember our example in the introduction? We had the idea of doing the training local on the client’s hardware, right where the client images live. We are going to simulate FedAvg with our client distributions with the function below!
from computation_fedavg_gd import fedavg
server_history , _ = fedavg(
function_clients=[multivariate1.evaluate, multivariate2.evaluate], # pass clients functions
function_eval=f_posterior_exact.evaluate, # for evaluationg the global posterior
communication_rounds = 1000,
gd_steps_local = 1,
theta=THETA,
)
ax = client_function_draw(J_exact) # draw global function
ax.scatter(
server_history[:, 0],
server_history[:, 1],
server_history[:, 2],
label="FedAvg",
c="red",
lw=5,
zorder=100,
)
ax.legend()
print("\u03F4_final: ",server_history[-1,:-1], "\n\u03F4_optimum:", mu_global_posterior)

ϴ_final: [ 0.64033788 -0.31200206]
ϴ_optimum: [ 0.67346939 -0.2433281 ]
Congratiulations! You made it. FedAvg reaches the global optimum. Through iteratively averaging our client updates, we trained one global model, which is now able to classify the images on client1 and client2 data optimally. Despite it is not the posterior modes (maximum) of any of the local distributions, we still found the best solution according to our a global cost function. But.. is that really always true? Does FedAvg always find the optimum of the global cost function, when we have non-iid client distributions?
3.3 How to mess with Federated Averaging
So far, FedAvg has been pretty successful. But remember how our client distributions have an heterogenous distribution (non-iid)?
Below, we will see, that FedAvg is not guaranteed to converge to the global optimum. Despite of the fact that our problem is very basic and a very minimal implementation of GD finds the optimum, FedAvg fails here. This happens, as we try to improve our communication efficiency by increasing our step size in the training:
communication_rounds = 20
gd_steps_local = 120
In the code below, observe how we fail to find the optimal solution using FedAvg.
server_history , _ = fedavg(
function_clients=[multivariate1.evaluate, multivariate2.evaluate], # clients
function_eval=f_posterior_exact.evaluate,
communication_rounds = 20,
gd_steps_local = 120,
theta=THETA,
)
ax = client_function_draw(J_exact, cmap="Purples") # plot global function
ax.scatter(
server_history[:, 0],
server_history[:, 1],
server_history[:, 2],
label="FedAvg",
c="red",
lw=5,
zorder=100,
)
fig = ax.legend()
print("\u03F4_final: ",server_history[-1,:-1], "\n\u03F4_optimum:", mu_global_posterior)

ϴ_final: [ 0.14657315 -0.12253487]
ϴ_optimum: [ 0.67346939 -0.2433281 ]
Explanations:
FedAvg does not find the optimal solution anymore. Instead of optimizing for the global posterior mode (the function you see in Purple above), we just average the local posterior modes. So in the end, we find a theta value, which drifts towards the client posterior modes. In iid scenarios, this wasn’t a problem. Practically speaking, if you and your friends are all taking the same pictures, FedAvg is more likeley to find an optimal solution for your model, compared to if you are taking pictures from different motives in different regions.
4. Our salvation: Posterior Averaging?
One thing we have not considerded at all, is the covariance of the Posterior of each client. If we could estimate more than just the argmax (== $\mu_{global}$) of our client posterior (e.g. using gradient descent), we could do better. Let’s estimate also the Sigma matrix also, and see what we can do.
compared to the pseudo code above for FedAvg the server code will remain almost the same.
class PA_server:
...
On the client we will change a bit of code. Most crucially, we will try to infer both, the Sigma and mu to average the posteriors on the server. There are some computational bottlenecks: In practice we would not be able to communicate a Matrix of the size of Sigma.
- with markov_chain_monte_carlo do some gradient descent steps and draw l samples
- using the samples, find the best sigma and mu for the samples from theta
- compute a update delta from sigma, sigma_estim and initial model value.
Especially with the help of the last step
class PA_client:
...
def train(self, theta_0):
samples_theta = markov_chain_monte_carlo ( theta_0 )
sigma_estim, mu_estim = estimate_best(samples_theta)
return delta = np.linalg.solve(sigma_estim, theta_0 - mu_estim)
# Disclaimer. This code is not actually meant to perform the same calculations as FedPa.
# It just shows, that once a sigma and mu is estimated, a better result than FedAvg can be achieved.
class PA_client:
"""A noisy client mimicking estimating the posterior"""
def __init__(self, multivariate):
self.mv = multivariate
def train(self, theta_0):
"""update finding the closed-form solution from the estimated sigma_estim, mu_estim
# goal: send an update which has size of theta_0.shape (n,)
:return: delta, array of shape theta_0.shape (and not sigma.shape (n,n)!!)
"""
sigma_estim, mu_estim = self._incorrect_mcmc(theta_0)
delta = np.linalg.solve(sigma_estim, theta_0 - mu_estim)
return delta
def _incorrect_mcmc(self, theta_0_ignored):
"""
estimates its client distribution. naive assumption, not actual mcmc!
doing nothing with theta_0 -> just adding some noise to the true sigma and mu!.
normally would use gd and Markov chain Monte Carlo approximation to find samples,
and then fit the best gaussian (sigma and mu) to it.
:return: sigma_estim and mu_estim
"""
sigma_estim = self.mv.sigma + np.random.normal(0, 0.1, self.mv.sigma.shape)
mu_estim = self.mv.mu + np.random.normal(0, 0.1, self.mv.mu.shape)
return sigma_estim, mu_estim
class PA_server:
"""Posterior Averaging server. Does the same as FedAvg server"""
def __init__(self, pa_client1, pa_client2):
self.pa_client1 = pa_client1
self.pa_client2 = pa_client2
def train_fedpa(self, theta_0: np.ndarray, lr_alpha: float, communication_rounds: int):
"""run training with 2 clients"""
theta = theta_0
history_server = [theta]
for i in range(communication_rounds):
# local epochs, client 1
delta_client1 = self.pa_client1.train(theta)
# local epochs, client 2
delta_client2 = self.pa_client2.train(theta)
# average deltas of all clients
theta = theta - lr_alpha * (delta_client1 + delta_client2) / 2
history_server.append(theta)
# return the theta
return np.asarray(history_server)
Disclaimer2: As you have seen, many parts of the code have been drastically simplified to fit in this notebook. Most prominently the mcmc is quite unrealistic, since we cannot directly observe mv.sigma. This might become more clear, when you set e.g. theta_0 = np.array([-10000,-10000]), where the posterior estimation would be infeasible. The original code is available at [6].
However the implementation above gives an intuition about Posterior Averaging, and uses just as many lines of actual python code as we would use in pseudocode.
Lets see, how this performs.
client1 = PA_client(multivariate1)
client2 = PA_client(multivariate2)
server = PA_server(client1, client2)
server_history = server.train_fedpa(theta_0=THETA, lr_alpha=0.1, communication_rounds=50)
accuracies = f_posterior_exact.evaluate(theta_vec = server_history)
ax = client_function_draw(J_exact, cmap="Purples") # plot global function
ax.scatter(
server_history[:, 0],
server_history[:, 1],
accuracies,
label="FedPa",
c="red",
lw=5,
zorder=100,
)
fig = ax.legend()
print("\u03F4_final: ", server_history[-1,], "\n\u03F4_optimum:", mu_global_posterior)

ϴ_final: [ 0.65818276 -0.20683045]
ϴ_optimum: [ 0.67346939 -0.2433281 ]
Finally, we made it! Our FedPA “Light” converged to the optimum!
4.1 FedPA: Beyond the simplified implementation
In this chapter, we already used Posterior Averaging to find our optimal $\theta$. As you can see in Figure2 below, instead of using GD on the clients, we estimated our covariance and our $\mu$ of the clients posterior distribution, and then send back the computed $\Delta$ .
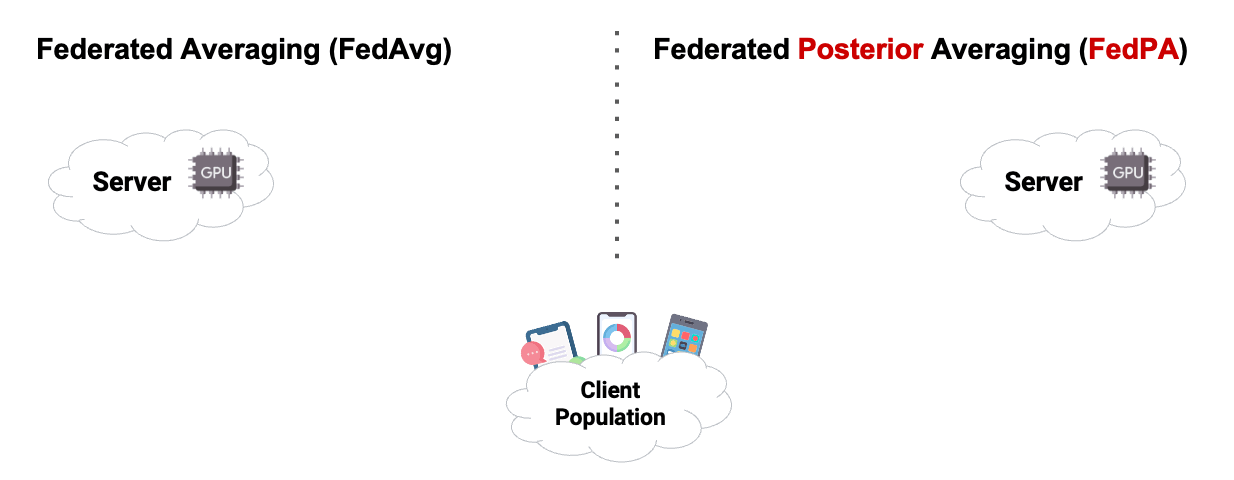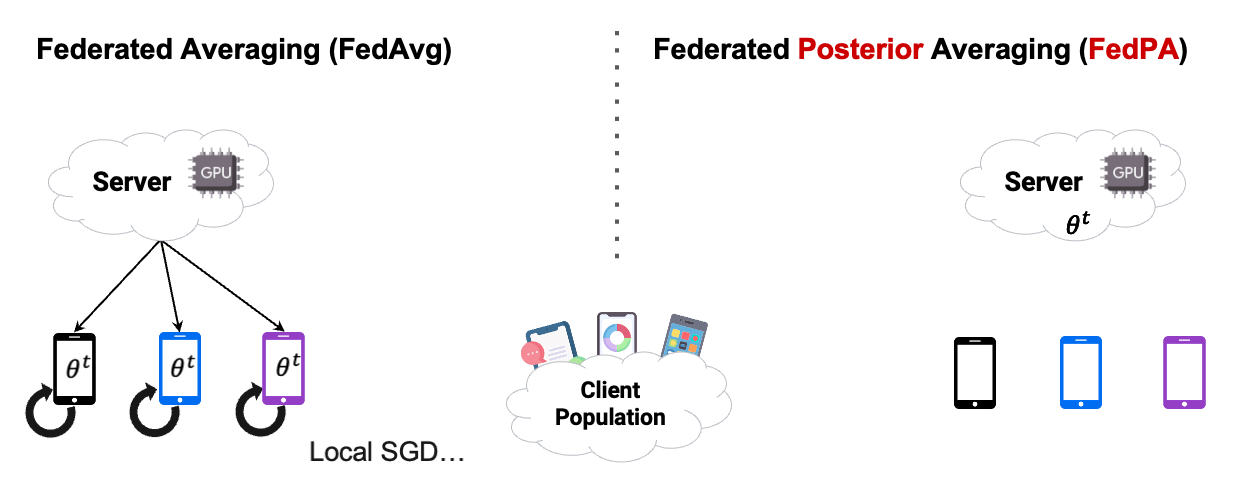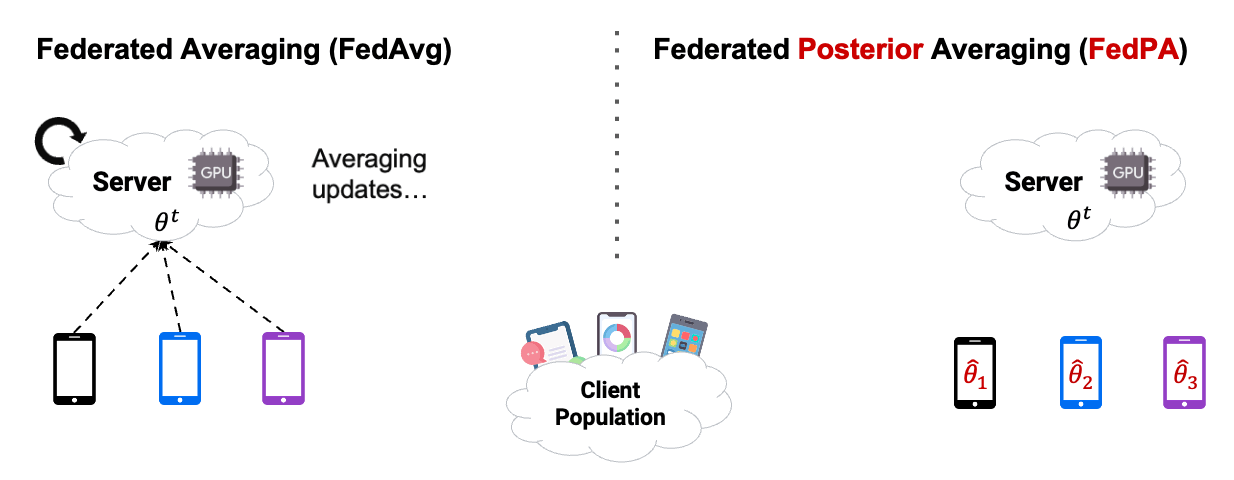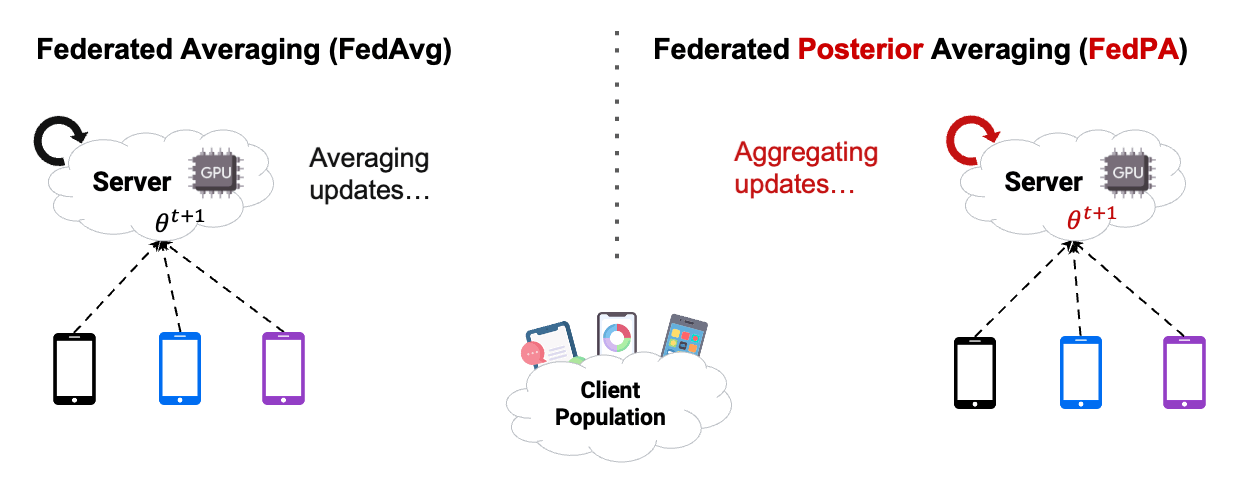
Reading the blog about FedPA from Maruan Al-Shedivat [1] was very valuable for me. I can warmly recommend to read and work through both, the blog and the code. This also motivated me in the decision to create this Notebook Blog, instead of ‘just’ a blog similar the authors’ original.
Part 5: Summary
In this blog, you have learned to:
- create two non-iid distributions for your initial problem with the images.
- You then derived the global posterior and used gradient descent to find the optimal paramters.
- Using Federated Learning, you applied FedAvg to this data setting and understood why this only found a suboptimal $\theta$.
- Ultimatley, using some gaussian estimation of the client posterior from the clients, you applied Posterior Averaging.
Thank you! If you have any kind of Feedback, feel free to contact me!.
Part 6: References
[1]: Federated Learning via Posterior Averaging: A New Perspective and Practical Algorithms, Al-Shedivat et al., Paper, 2021
[2]: Communication efficient learning of deep networks from decentralized data, McMahan et al., Paper, 2017
[3]: OM PriCon2020: OpenMined: ‘Advances and Open Problems in Federated Learning’ - Peter Kairouz, Peter Kairouz, Presentation, 2020
[4]: An inferential perspective on federated learning, Al-Shedivat, Blog, 2021
[5]: The Matrix Cookbook, K. B. Petersen and M. S. Pedersen, 2012
[6]: Federated Learning via Posterior Averaging, Al-Shedivat et al., Code, 2021